Troubleshooting
Warning
These pages contain information intended mainly for Bloch staff members. If you are not staff, you must not attempt anything described here that involves changing settings, adjusting hardware or calling facility on-call services
The ‘restart sardana’ shortcut on the beamline Linux computer desktop will restart the pool and the macroserver and can fix a variety of problems. The GUI for this can be launched from a terminal with
sardana-restart --widgetIf something is wrong but you don’t yet know what the cause is, a good starting point can be to run the ‘Checkup’ macro. This is launched from the ‘ControlGUIs’ folder on either of the windows measurement computers, and will highlight any beamline components that are in an unusual state.
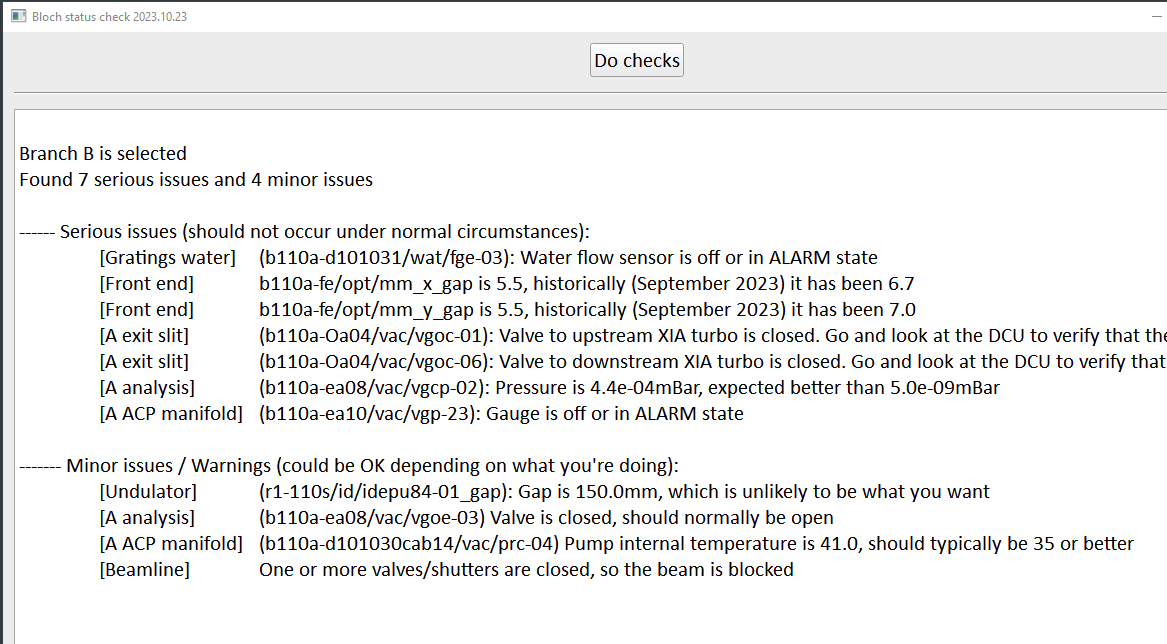
A third angle of attack is to open Astor and look for device servers that are in fault or not running, but should be. Often a restart of the server within Astor is sufficient to fix the problem.
If you cannot open the beamline front-end, check whether the hutch has been searched.
If the undulator is not responsive even after a sardana reset, or if you still cannot open the front end despite searching the hutch, it can be helpful to ask the operator if they can see any issues from their side (use the chat window, or go in person)
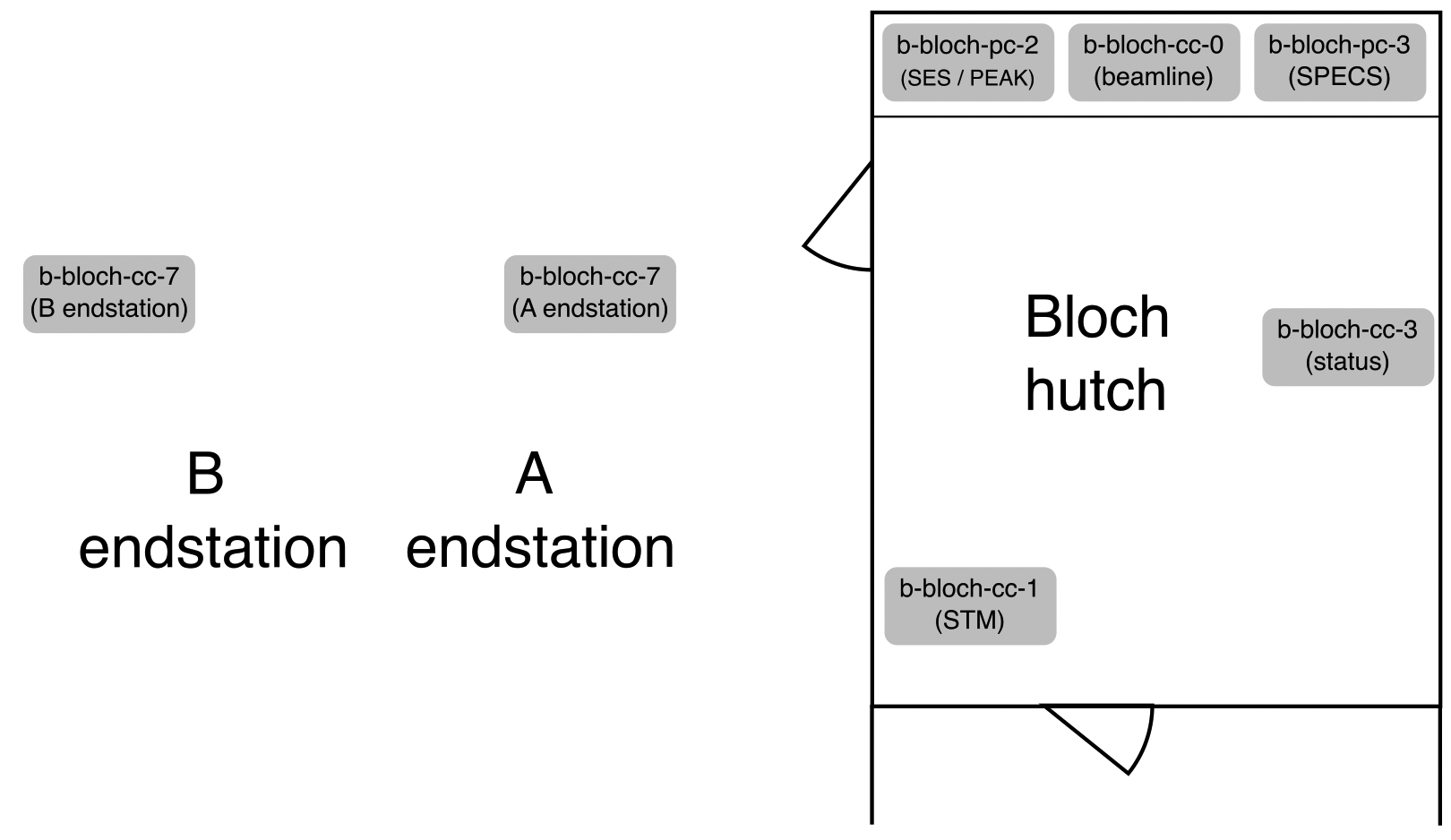
The computers at the beamline and their addresses in case you need to remote connect to them are shown here:
On-call support options
Phone numbers are listed in this elogy post (blue/white network only)
Beamline
If the heatload on M1 is too high and either thermocouple goes above 40° C, the beamline will close. These thermocouple values are reported in the M1 pitch feedback panel. The solution is to reduce the frontend mask xgap and ygap by a few millimeters, wait until the temperature falls and then try to re-open the beamline.
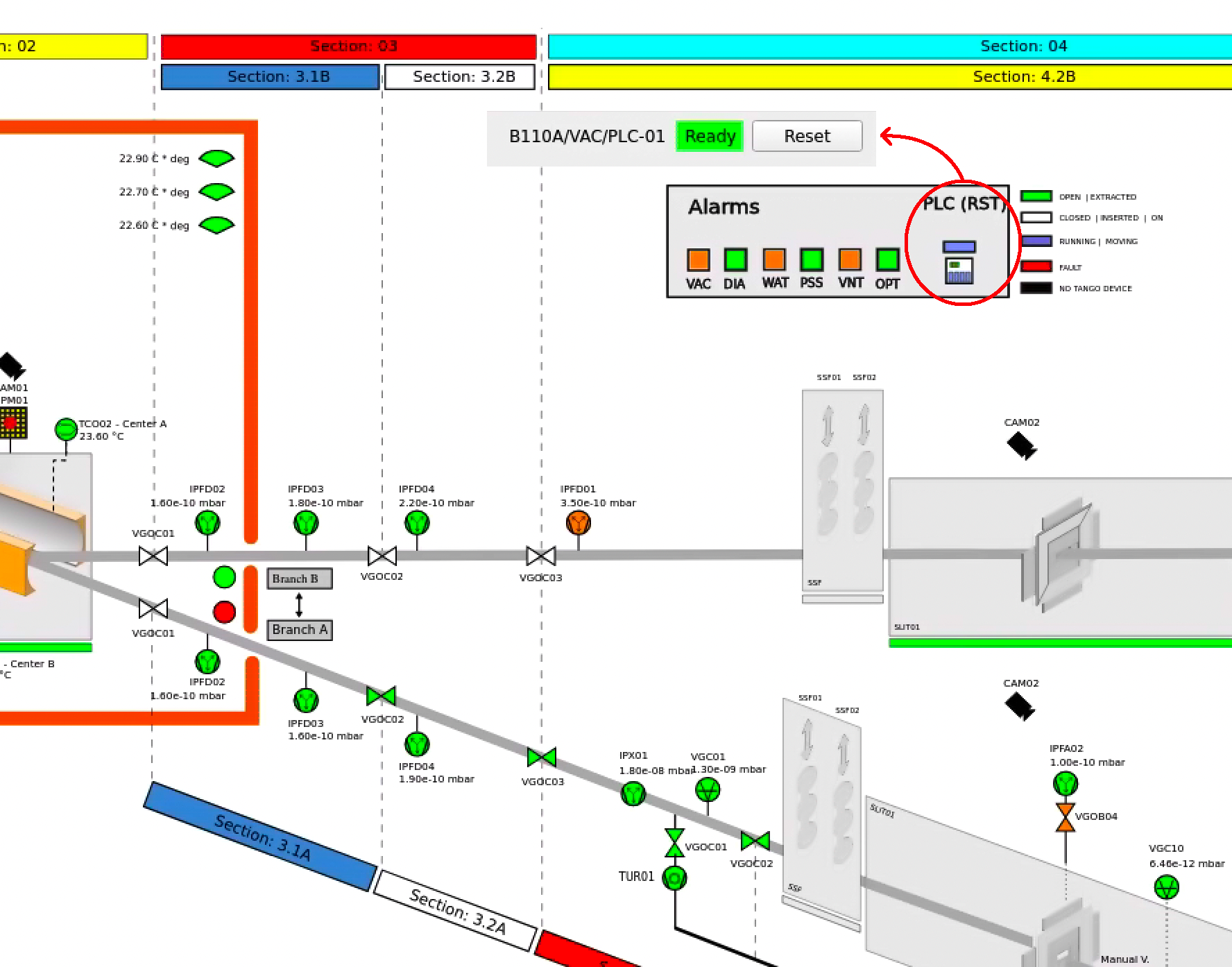
Sometimes PLC errors must be cleared in order to recover. This can be done (at any time, with no risk) by right-clicking on the ‘PLC (RST)’ button in the beamline synoptic:
Sample cameras
If you launch a video feed of the sample camera in Pylon Viewer and get nothing but error frames, see the ‘frame errors’ section of this page: Basler sample cameras
A-endstation
The Carving motion macros (e.g. to go between transfer and measurement positions) will refuse to run if the gate valve between the RDC and the analysis chamber is open
The Carving motion macros must not be stopped once they have begun. If this happens for any reason (user presses a cancel button, control system crashes…), the manipulator will find itself outside of a defined software bounding box and will not know how to safely move. In this situation the ‘safe’ guarded axis controls are locked. Recovering from this involves using the unsafe ‘raw’ motor controls to drive the manipulator back inside the closest bounding box. Use extreme caution when doing this! Catastrophic damage could occur if it is done blindly. To see the bounding box limits and access the unsafe motors, switch the Bloch controls GUI on the beamline computer to staff mode, then re-launch the Carving contorl panel and go to the ‘Setup’ tab at the bottom. The problem will be solved automatically when one row of the table is all green (i.e. conditions for one bounding box are satisfied).
The endstation control computer (b-bloch-cc-7) runs the two large screens mounted above the hutch door. Sometimes the connection to these is flakey, and it can happen that the login panel (after a restart for example) will be hidden on one of those monitors. Unplug them from the computer (white HDMI cables) to force the PC to only use the two smaller screens.
SES
The interface connecting SES to the manipulator and to the monochromator relies on a certain process being alive on a remote virtual computer somewhere. If this goes down (as can happen during e.g. a power cut), the symptom will be that SES cannot read manipulator positions or monochromator energy, and the UI will feel extremely sluggish as it repeatedly attempts to poll these devices and times out waiting for a reply. You need to contact KITOS to bring the required service back. It may help to direct them to the bottom part of this elogy post.
Another common reason for SES becoming very sluggish is the number of regions in the current sequence file growing too long. The time SES needs to process the file increases nonlinearly with the number of entries, and can reach several seconds when there are 12+ regions. The fix is to delete unused regions, or start a new sequence file.
If the live detector viewer window in SES is showing a perfect white grid pattern, it usually means it could not connect to the sample camera. This could be because the camera is not connected, or because PEAK is in-use or was previously in-use and did not shut down properly. If PEAK is the culprit, you will see in Pylon Viewer that the camera has been renamed ‘PEAK camera’. Solve this by reconnecting to PEAK and then trying again to close it down in the expected way.
If you accidentally close the live detector viewer window, it will come back if you restart SES. If it doesn’t (or you don’t want to restart), go Installation>Instrument>Detector Interface Setup>Filter:Real-time Monitor Setup
Motor issues
The most common icepap issues are motors powering off due to closed loop errors or due to overcurrent errors. In both cases the motor involved is powered down, and cannot be powered on again until the error is cleared.
Warning
Both error types often happen randomly, and do not indicate a real underlying problem. But if you ever have to do this multiple times within a short space of time, something is probably wrong and you should investigate (slipping encoder, something needs lubricating…)
Within icepapcms, the nature of the problem can be confirmed by invoking a console (you can can right click on the relevant rack in the left hand panel to do this directly, skipping the need to type in the rack address). Status information is obtained by (<axis number>:?VSTATUS) (e.g. for the Carving y-axis, 2:?VSTATUS).
Closed loop errors
This occurs when the encoder and the stepper fall out of sync (e.g. motor turns but encoder doesn’t increment). This can be fixed by either issuing an esync command from a spock terminal (ipap_esync <motor_sardana_name_or_tango_alias>) OR in icepapcms - disable closed loop mode, send config to board, enable closed loop mode, send config to board, attempt to power on again.
Overcurrent errors
These are more difficult to deal with. If you are within standard working hours, call KITOS for support. If not, the currently recommended procedure is:
In icepapcms, power down all other motors in the same rack as the problem motor
Issue a RESET command in the icepap console (
RESET <rack number>)Power cycle the rack (physical switch at the back)
It may be necessary to re-enable one or more axes by holding up the ‘enable’ toggle switch(es) on the front panel for a few seconds until the LED turns green.
You should now be able to power on the motor again in icepcms
If you’re desparate for more information, good luck finding what you need in the icepap manual here.